Arkkitehtuurit
On tärkeää muistaa, että data-alusta ei ole yksittäinen tuote vaan kollaasi eri työkaluja. Loppukäyttäjän näkökulmasta alusta voi olla "se meiän firman power bi", mutta todellisuudessa kokonaisuus koostuu useista eri työkaluista. Lisäksi eri yritysten data-alustat voivat olla keskenään hyvin erilaisia. Yrityksellä voi olla yksi monoliittinen, keskitetty tietoalusta, tai hyvinkin hajautettu data-alustojen patteristo.
Warning
Ei ole olemassa ns. parasta alustaa. On olemassa vain trade-offeja, joita yrityksen tulee puntaroida omassa kokoluokassaan, kontekstissaan ja tavoitteissaan. Jos haluat syväsukeltaa aiheeseen, suosittelen Joe Reisin ja Matt Housleyn kirjaa Fundamentals of Data Engineering sekä Martin Kleppmannin kirjaa Designing Data-Intensive Applications, 2nd Edition.
Yleisnäkymä
50,000 jalan näkymä

Kuvio 1: Karkea 50,000 jalan näkymä data-alustan arkkitehtuuriin.
Yllä olevan graafin (Kuvio 1) komponentit ovat vasemmalta lukien:
- Sininen: Lähdejärjestelmät (source system)
- Datan alkuperäiset lähteet, kuten operatiiviset tietokannat.
- Hopea: Sisääntuonnin työkalut (ingestion tools)
- Kerros, joka louhii tai vastaanottaa datan tietoalustaan.
- Oranssi: Toistaiseksi mustana laatikkona nähty kokonaisuus, joka sisältää tallennuksen ja laskennan (eng. storage & compute.)
- Violetti: Datan tarjoilukerros (eng. serving layer) on loppukäyttäjän näkymä dataan. Tyypillinen esimerkki on BI-työkalu kuten Power BI, Qlik tai Tableau, mutta kyseessä voi hyvin olla myös käyttötarpeeseen räätälöity verkkosivusto (esim. Plotly, JavaScript D3, React) tai suoraa kantayhteyttä muistuttava connector (esim. ODBC connector). Tietoalusta voi myös puskea dataa ulos, jolloin sitä ei ylipäätänsä noudeta, vaan se syötetään järjestelmään X.
- Ihmisfiguuri: Tietoalustan loppukäyttäjä. Heidän tarpeitaan varten koko alusta luodaan. Loppukäyttäjiä voi olla useita erilaisia, kuten myynti, ylin johto, tutkimus ja tuotekehitys, ohjelmistonkehittäjät, tietoturva-asiantuntijat, ja niin edelleen.
30,000 jalan näkymä

Kuvio 2: Edellistä kuviota yksityiskohtaisempi 30,000 jalan näkymä data-alustan arkkitehtuuriin.
Huomaathan, että yllä olevassa Kuvio 2:ssa on jo valittu tiettyjä palveluita esimerkeiksi. Data-alustan ei ole pakko käyttää medaljonkiarkkitehtuuria (bronze, silver, gold) eikä mitään muutakaan yksittäistä valittua tuotetta. Työkalut ovat esillä liiallisen abstraktion välttelemiseksi.
Datan määrä
Anti Big Data: DuckDB
Kaikki eivät niele täysin purematta big datan tarpeellisuutta kaikissa maailman yrityksissä. Tästä esimerkkinä on yhden noden kolumnaarinen OLAP-engine nimeltään DuckDB. DuckDB ei ole perinteinen tietokantapalvelin vaan in-process tietokanta. Tietokanta voi olla tiedostossa (esim. db.duckdb) tai käytössä voi olla DuckLake, jolloin kannan metadata on katalogitiedostossa (tai tietokannassa) ja data tallennetaan tiedostoina (esim. Parquet) tiedostojärjestelmään tai pilveen.
Huomaa, että 50,000 jalan päästä katseltuna kaikki arkkitehtuurit näyttävät yllättävän samalta. Periaatteessa DuckDB:n arkkitehtuuri on myös vähän lähempääin katsottuna yllättävän samanlainen kuin modernien tietoalustojen "big data"-versionsa. Yllä esitelty 30,000 jalan näkymä on hyvinkin toteutettavissa DuckDB:n avulla.
Tehtävä
Lue MotherDuckin Jordan Tiganin kirjoitus Big Data is Dead. Mihin Jordan perustaa väitteensä?
Tip
DuckDB on oikeasti olemassa oleva projekti, joka on julkaistu avoimen lähdekoodin lisenssillä. DuckDB on SQL-tietokanta, joka on suunniteltu toimimaan yhdellä tietokoneella. DuckDB on myös yksi esimerkki siitä, että data-alustan ei tarvitse olla monoliittinen, vaan se voi koostua useista eri työkaluista.
Alla esimerkki DuckDB-tyylisestä alusta, jossa kaikki data mahtuu yhden tietokoneen rammiin vähintään paloiteltuna. Huomaa, että arkkitehtuuri ei loogisella tasolla eroa kovinkaan paljon esimerkiksi yllä olevasta 30,000 jalan näkymästä, vaikka fyysisellä tasolla ero onkin merkittävämpi (yksi tietokone vs. monta hajautetun laskennan klusteria.) Kuvan alusta on jotakin, mikä on täysin tehtävissä 3 opintopisteen kurssin aikana.
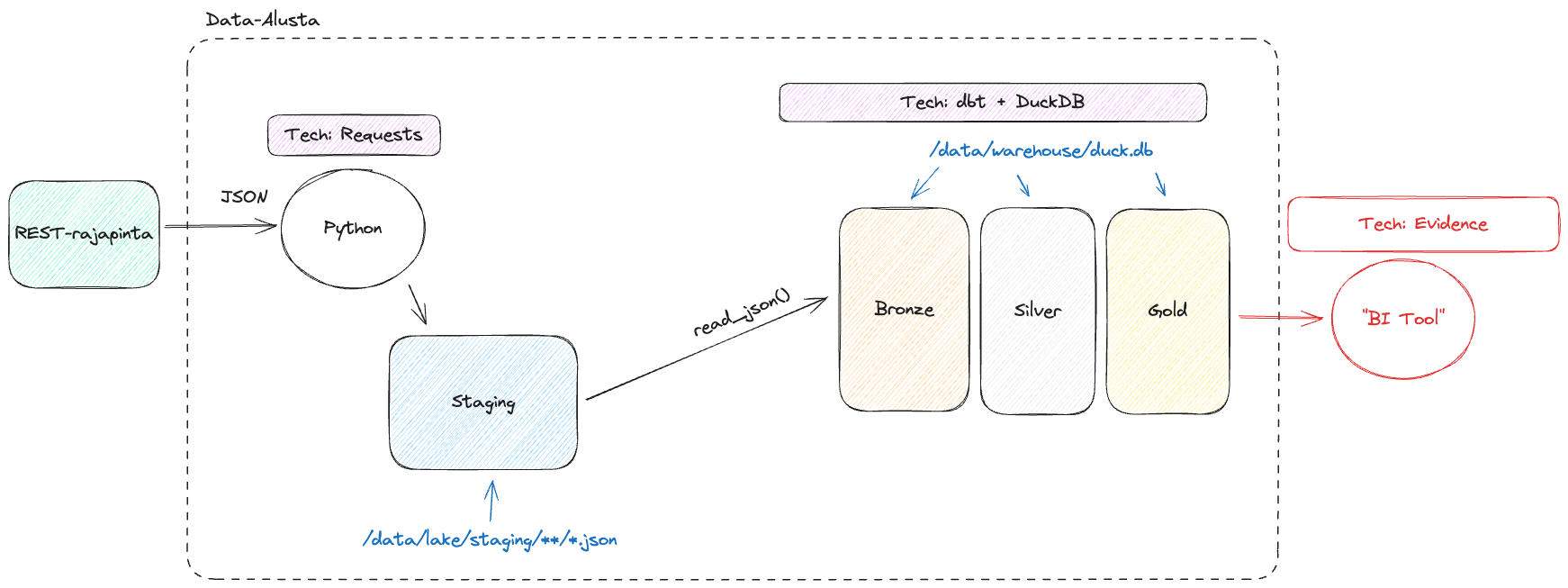
Kuvio 3: Yhden koneen ja yhden tietolähteen data-alusta. Alustaa on helppo jatkaa suuremmaksi. Siihen voi tuoda uusia tietolähteitä, siirtää laskennan pilveen, siirtää tallennuksen pilveen, vaihtaa BI-työkalun, ottaa orkestrointiin dbt Cloudin ja/tai Airflow:n. Oikein käytettynä alustasta voisi olla hyvinkin realistista bisneshyötyä.
Tehtävä
Vertaa yllä esiteltyä alustaa Christophe Blefarin Fancy Data Stackiin. Kuinka paljon yhtäläisyyksiä ja eroja löydät?
Pro Big Data: Muut
Mikäli voidaan olettaa, että dataa on paljon, ja että dataa on useista eri lähteistä, on todennäköistä, että dataa ei voida tallentaa yhdelle koneelle (esim. db.duckdb-tiedostoon). Vaikka data hajautettaisiin pilvipalvelun tarjoamaan loputtamasti skaalautuvaan tallennustilaan eri tiedostoihin partitioituina, sen prosessointi yhdellä koneella ei välttämättä ole realistista. Tällöin tarvitaan hajautettua laskentaa.
Big data -tyyliset modernit tietoalustat ovat siis, kuten aiemmin todettua, 50,000 ja 30,000 jalan etäisyydeltä katsottuna loogisesti hyvinkin samanlaisia kuin sinun tietokoneeseesi viritelty DuckDB, jossa kaikki kerrokset (tietojen lataus, mallinnus ja esitys) pyörivät yhden tietokoneen muistissa. Yhden tietokoneen työkalut kuten Pythonin Pandas-kirjasto, perinteinen Jupyter Notebook sekä DuckDB eivät edusta hajautetun laskennan työkaluja, joten ne menevät vaihtoon big dataa käsitellessä. Yritys voi valita ainakin seuraavista vaihtoehdoista:
- Hallittuja, suljetun lähdekoodin pilvipalveluita
- Hyperscalereiden (AWS, Azure, GCP) omat ratkaisut
- Muut SaaS-tarjoajat (Snowflake, Fivetran)
- Hallittuja, avointa lähdekoodia olevia pilvipalveluita
- Hyperscalereiden avoimen lähdekoodin versiot (esim. AWS MSK = Apache Kafka)
- Muut SaaS-tarjoajat (esim. Confluent = Apache Kafka, Databricks = Apache Spark)
- Itse hostattuja avoimen lähdekoodin palveluita
- Apache Spark, Kafka etc.
Yllä olevan listan itemit eivät ole toisiaan poissulkevia. On mahdollista ottaa hallittu alusta esimerkiksi tietovarastoksi (esim. Snowflake), mutta koodata tee se itse -periaatteella ohjelmisto, joka kirjoittaa datan tietoalustaan. On myös mahdollista koodata koko ratkaisu itse, mitä valtavat IT-jätit kuten Google ja Netflix tekevätkin. Jätetään tämä vaihtoehto kuitenkin käsittelemättä useimmiten täysin epärealistisena.
Käytännön toteutuksia
Oletetaan, että Yritys X tarvitsee nimenomaan big dataan kykenevän, hajautetun alustan. Alla on pari esimerkkiä, jotka noudattavat aiemmin esiteltyjä hallittuja (eng. managed) ja itse hostattuja (eng. self-hosted) vaihtoehtoja. Huomaa, että itse hostattu voi kuitenkin olla pilvipalvelussa (esim. AWS EC2) tai omassa konesalissa (eli on-premise.)
SaaS
Yritykselle itselleen hyvin yksinkertainen ratkaisu on ostaa ratkaisut SaaS (Software as a service) -palveluntarjojilta palveluina. Hintalappu saattaa osoittautua korkeammaksi kuin räätälöidymmillä vaihtoehdoilla, mutta toisaalta ratkaisu on nopea ja helppo ottaa käyttöön.
Suomessa on ainakin 2025-2026 tienoilla ollut Snowflake kovin pinnalla; tämä näkyy esimerkiksi Helsinki Data Weekin keskusteluissa. Siksi otan tässä tietovarastona esimerkiksi Snowflaken. hallinnoi AWS/Azure/Google tallennustilan, laskennan ja muun. Data ja laskenta ovat heidän pilvitileillään. Annetut tuotteet ovat esimerkkejä. Snowflaken voi korvata esimerkiksi Dremio:lla ja Tableaun esimerkiksi Qlik Sense:llä tai Power BI Pro:lla. Fivetran:n voi korvata esimerkiksi Stitch:llä. Dbt:n voi korvata esimerkiksi Matillion:lla tai jopa HashiCorp:n Terraform:lla.
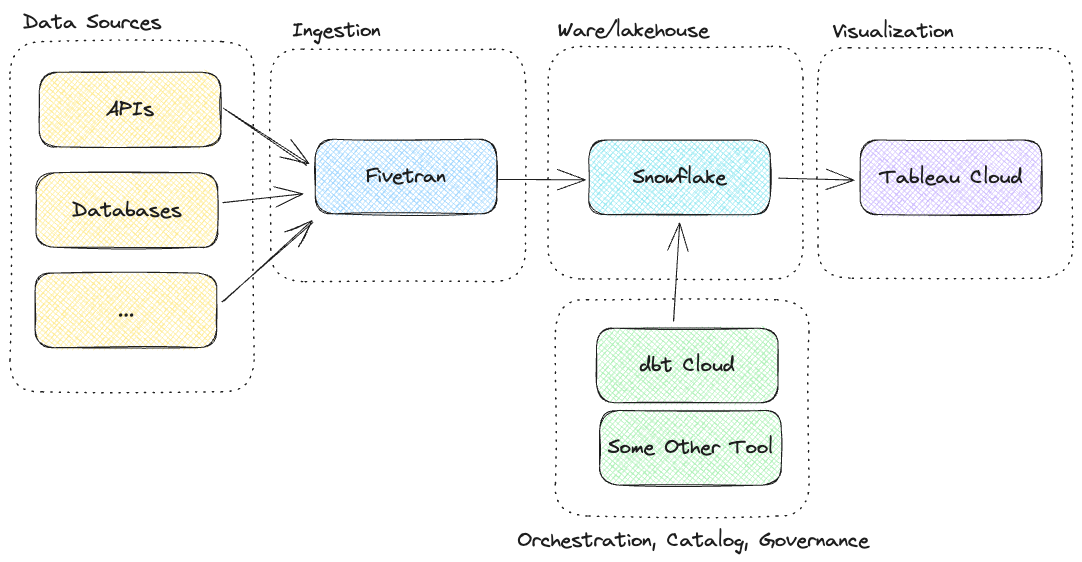
Kuvio 4: SaaS-ratkaisu, jossa kaikki on ostettu palveluna.
Hadoop-like
Hadoop-ekosysteemi on toteutettavissa joko itse hostattuna, Databricksin avulla tai käyttäen hyperscalereiden tarjoamia vastaavia ratkaisuja. Alla taulukossa muut paitsi Databricks, joka esitellään alempana.
| Open Source | AWS | Fabric (Azure) | GCP | |
|---|---|---|---|---|
| Ingestion | Airbyte | AWS Lake Formation, DMS | Data Factory (Azure Data Factory) | Data Fusion |
| Orchestration | Airflow | Data Pipeline, MWAA (Airflow) | Data Pipeline (Azure Data Factory) | Dataproc |
| Streaming | Kafka | Kinesis, MSK (Kafka) | Real-Time Intelligence (Event Hubs) | Pub/Sub |
| SQL (Query) | Hive | Athena, Redshift | Data Warehouse (Azure Synapse Analytics) | BigQuery |
| Storage | HDFS | S3 | OneLake (Azure Data Lake Storage) | Cloud Storage |
| Compute | Spark | EMR | Fabric Data Engineering (Azure Synapse Spark) | Dataproc |
| Auth | ??? | IAM | Microsoft Entra ID (Azure Entra ID) | Cloud IAM |
| BI | Superset | QuickSight | Power BI (Same in both) | Looker |
Note
Taulukon Fabric-sarake edustaa Microsofin uutta, pilvipohjaista data-alustaratkaisua, joka yhdistää useita eri työkaluja ja palveluita yhteen kokonaisuuteen. Vanhempi vastine on suluissa perässä. Huomaa, että aivan 1:1 vastinetta ei aina kaikissa tilanteissa löydy, koska uusi, syntynyt kokonaisuus voi erota entisistä työkaluista granulariteetiltaan ja toiminnaltaan. Tässä mielessä Fabric muistuttaa hieman one-stop-shop -ratkaisua, mutta aivan kuten Databricks tai Snowflake, se ei kuitenkaan ole täysin monoliittinen ratkaisu.
Warning
Lista on kasattu 2025 ja voi vanhentua nopeasti.
Valmiita kokonaisuuksia
Hyperscalerit (eli AWS, Azure, GCP, jne.) tarjoavat omia alustojaan, jotka joko koostuvat pienemmistä irtopalasista (esim. AWS Glue + EMR + S3 + ...) tai ovat enemmän monoliittisia (esim. Microsoft Fabric).
Lisäksi yksittäiset SaaS-tarjoajat (esim. Databricks, Snowflake, Dremio, jne.) tarjoavat alustoja, jotka ovat syöneet sisäänsä sellaisen määrän eri ominaisuuksia, että ne toimivat ns. valmiina kokonaisuuksina, vaikkakin mahdollistavat myös muiden työkalujen integroimisen niiden kylkeen.
Tämä kenttä on sen verran eläväinen, etten koe hyödylliseksi listata kaikkia verkkosivulla. Näitä on helpompi plärätä nopeasti videotallenteessa esim. MAD Landscapen avulla.