K-Means
Ryvästys
Kämäräisen käyttämä suomennos klusteroinnista on ryvästys 1. Hän myös esittää ajatuksen, että useimmat ryvästysmenetelmät ovat vuosikymmeniä vanhoja, mutta niitä kehitetään yhä.
"Moni koneoppimisen tutkijoista pohtiikin, odottaako ohjaamaton oppiminen samanlaista kehitysloikkaa, joka ohjatulle oppimiselle tapahtui syväoppimisen (deep learning) myötä 2010-luvulla"
— Joni Kämäräinen 1
Aiemmin esiteltyä k-NN:ää ja nyt käsiteltävää k-means algoritmia yhdistää kirjain k, mutta niiden merkitys on eri. k-Meansin kohdalla k tarkoittaa n_clusters eli ryppäiden määrää, kun taas k-NN:ssä k tarkoittaa naapureiden määrää. Toinen merkittävä ero algoritmien välillä on, että k-means ei ole luokittelualgoritmi, vaan – kuten otsikosta varmaan arvaatkin – rypästysmenetelmä. Kyseessä on siis ohjaamaton oppiminen (engl. unsupervised learning), mikä tarkoittaa, että opetusnäytteillä ei ole ennalta tiedettyjä luokkia 1. Nämä ovat siinä mielessä tärkeitä algoritmeja, että maailmassa on tarjolla hyvin pieni selkeästi annotoitu määrä dataa suhteessa täysin kuratoimattomaan dataan. Kämäräinen mainitsee myös SOM:n (Self-Organizing Map), joka on maailmalla tunnetun Teuvo Kohosen kehittämä 1980-luvulla. Tämäkin kehityskulku yhä jatkuu, ja tuoreehkoja käänteitä esitellään katsausartikkelissa A Survey on Recent Advances in Self-Organizing Maps 2. Me pitäydymme kuitenkin tällä kurssilla ryvästysmenetelmissä ja sivuutamme muut ohjaamattoman oppimisen menetelmät.
Ryvästysmenetelmät voi jakaa ainakin kahteen perheeseen: neliövirhemenetelmiin ja hierarkisiin menetelmiin 1. Suomalaisten termien sijasta jaan tässä materiaalissa ne vastaavasti seuraaviin kolmeen perheeseen, mutta olisi mahdollista jakaa se myös muihin (esim. grid-based) 3:
- Partition-based clustering: k-Means, MeanShift
- Hierarchical:
- Agglomerative Clustering: AgglomerativeClustering
- Divisive Clustering: MST
- Other: SOM, CHAMELEON
- Density-based: DBSCAN, OPTICS
K-Means vaiheet
K-means pyrkii minimoimaan klusterien sisäisen hajonnan eli pisteiden etäisyydet omaan klusterikeskukseen. K-Means on lähes yhtä simppeli algoritmi kuin k-NN. Aivan kuten k-NN, myös k-meansiä voi käyttää n-ulotteisessa avaruudessa, mutta visualisoinnin vuoksi käytämme tässä esimerkissä vain 2-ulotteista avaruutta. Koulutuksen vaiheet voidaan tiivistää seuraavasti 4:
- Valitse
kklusteria, joihinmnäytettä klusteroidaan. - Päätä tai arvo (x,y)-koordinaatit
kklusterikeskuksille. - Nimitä kukin piste kuuluvaksi lähimpään klusteriin (\(m\) -> \(m_k\))
- Laske keskiarvo (x,y) jokaiselle \(m_k\) havainnolle. Siirrä klusterikeskukset näihin (x,y)-koordinaatteihin.
Vaiheet 3-4 toistetaan kunnes klusterikeskukset eivät enää muutu (tai jokin muu lopetusehto täyttyy).
Vaiheet kuvina
Alla esimerkki, joka on rautakoodattu toimimaan tasan 2-ulotteisessa avaruudessa.
Data on täysin kuvitteellista, mutta mikäli se helpottaa, niin voit kuvitella x:n ja y:n arvojen taustalle jonkin ilmiön. Esimerkiksi:
- x-akseli:
 silmälasien vahvuus (± 2.5)
silmälasien vahvuus (± 2.5) - y-akseli:
 ananas-pizzatäytteen tykkäysaste (± 2.5 σ)
ananas-pizzatäytteen tykkäysaste (± 2.5 σ)
Info
Tällöin datasetin oikean ylälaidan rypäs, jonka keskipiste on noin \((1, 1)\), koostuu kaukonäköisistä -pizzan ystävistä. Datasetin perusteella vaikuttaisi, että ananaksesta tykkääminen pizzan täytteenä on kaukonäköistä puuhaa. Kenties datasta puuttuu jokin merkittävä piirre, kuten se, että onko kyseessä purkki- vai tuoreananas?
Vaihe 1: Valitse k
Valitaan klustereiden määrä k eli n_clusters. Tässä esimerkissä valitaan k=3. Data on generoitu siten, että me satumme tietämään klustereiden määrän etukäteen. Tässä yksinkertaisessa esimerkissä se olisi myös nähtävissä paljaalla silmällä katsomalla pistekuvaajaa.
Vaihe 2: Alusta klusterikeskukset
Huomaa, että alla olevan kuvaajan (Kuva 1) pisteet kuuluvat aluksi -1 klusteriin, mikä piirretään tässä tapauksessa harmaana pisteenä. Dataa ei ole annotoitu, joten alkutilanteessa emme tiedä datasta mitään.
Klusterilla on id, joka on kokonaisluku range(k) eli tässä tapauksessa 0, 1, 2. Niillä on kullakin oma ei-harmaa värinsä.
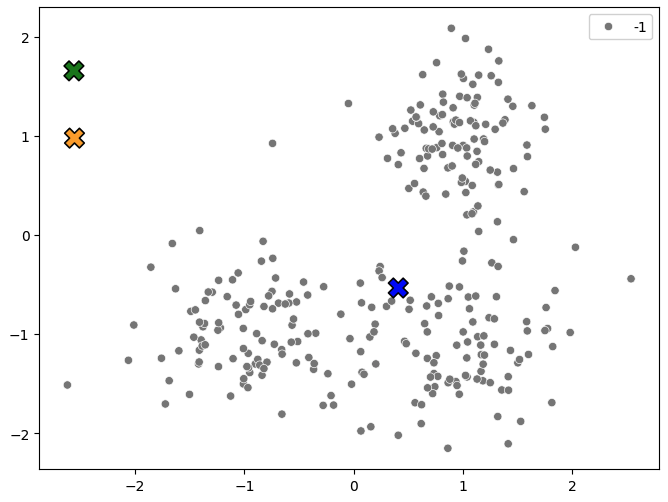
Kuva 1: Klusterikeskukset satunnaisesti valittuna. Sallimme tässä esimerkissä arvonnan käyttää mitä tahansa arvoja välillä -3 ... 3 eli jopa pisteavaruuden ulkopuolelta.
Tip
Klusterien lokaatiot ovat arvotut. Käytännössä parempi alustus olisi valita \(k\) satunnaista pistettä ja asettaa keskuksen niihin: tämä demon lähestymistapa on valittu, jotta muutokset olisivat suurempia.
Mitäkö scikit-learn käyttää? Katso KMeans-dokumentaatiosta.
Vaihe 3: Nimeä pisteet lähimpään klusteriin
Klusteriin kuuluvan pisteen määrittämiseksi lasketaan etäisyys jokaisen klusterin keskipisteen ja pisteen välillä. Piste kuuluu siihen klusteriin, jonka keskipiste on lähimpänä pistettä. Tämä tehdään alla olevalla koodilla:
@dataclass
class Point:
x: float
y: float
cluster: int = -1
@dataclass
class Centroid:
x: float
y: float
cluster: int
def assign_points_to_centroids(points: list[Point], centroids: list[Centroid]):
for point in points:
# Euclidean distances to the three centroids
distances = [
((point.x - centroid.x)**2 + (point.y - centroid.y)**2)**0.5
for centroid in centroids
]
# Fetch the centroid with the smallest distance
indx = distances.index(min(distances))
closest = centroids[indx]
# Assign the point to the closest centroid
point.cluster = closest.cluster
return points
Tip
Koska datalla ei ole varsinaisesti "labelia", käytämme jatkossa sanaa "cluster" viittaamaan klusteriin, johon piste kuuluu, ja välttelemme sanan "label" käyttöä.
Vaihe 4: Päivitä klusterikeskukset
Kun jokainen piste on määritetty kuuluvaksi lähimpään klusteriin, lasketaan jokaisen klusterin pisteiden keskiarvo. Tämä keskiarvo on uusi klusterikeskus. Tämä tehdään alla olevalla koodilla:
def compute_new_centroid_locations(points: list[Point], centroids: list[Centroid]):
for centroid in centroids:
# Subset of points matching the i'th cluster
cluster_points = [point for point in points if point.cluster == centroid.cluster]
# Mean of columns (x and y)
n = len(cluster_points)
# If this cluster was too far away from any points,
# move it to the middle of ALL points
if n == 0:
centroid.x = sum([point.x for point in points]) / len(points)
centroid.y = sum([point.y for point in points]) / len(points)
continue
# New x and y candidates
new_x = sum([point.x for point in cluster_points]) / n
new_y = sum([point.y for point in cluster_points]) / n
# Stopping condition
if new_x == centroid.x and new_y == centroid.y:
print(f"We have met the stopping condition.")
return None
centroid.x = new_x
centroid.y = new_y
return centroids
Alla olevassa kuvassa (Kuva 2) näkyy klusterikeskukset ja niiden lokaatiot ensimmäisen iteraation jälkeen. Klusterikeskukset ovat siirtyneet lähemmäs klusteriin kuuluvia pisteitä. Huomaa, että vihreä klusteri (cluster 2) arvottiin epäonniseen paikkaan, ja sitä lähimpänä ei ollut yksikään piste. Tämän vuoksi klusterikeskus siirtyi keskelle kaikkia pisteitä (ks. yllä olevasta koodista n == 0-kohta).
Tip
Vaihtoehtoinen tapa ratkaista ongelma olisi arpoa klusterikeskukset lähemmäs kuuluvia pisteavaruuden keskustaa. Yksi monista tavoista on se, että ottaa random.sample(points, k)-funktiolla k-kappaletta satunnaisia pisteitä ja asettaa ne klusterikeskuksiksi.
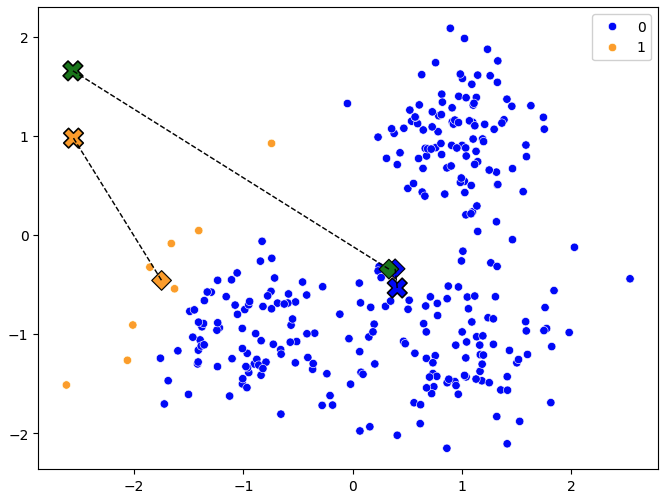
Kuva 2: Klusterikeskukset siirtyneet lähemmäs klusteriin kuuluvia pisteitä. Ruksi edustaa vanhaa lokaatiota, pystyneliö uutta lokaatiota.
Vaihe N: Toista kunnes klusterikeskukset eivät enää muutu
Huomaa compute_new_centroid_locations-funktion palauttama None, joka kertoo, että klusterikeskukset eivät enää muuttuneet. Tämä on meidän lopetusehto. Voimme siis kouluttaa algoritmin loppuun muutoin loppumattomassa silmukassa. Järkevä koodaaja laittaisi myös max_iter-parametrin, joka estäisi silmukan jatkumisen loputtomiin. Se puuttuu tästä esimerkistä.
while True:
# Take a deep copy for plotting purposes
prev_centroids = deepcopy(centroids)
# Compute
points = assign_points_to_centroids(points, centroids)
centroids = compute_new_centroid_locations(points, centroids)
if centroids is None:
break
plot_data(points, prev_centroids, centroids)
Klikkaa plot_data koodi esiin
def plot_data(
points:list[Point],
centroids:list[Centroid],
future_centroids:list[Centroid]=None):
# Set up canvas
plt.figure(figsize=(8, 6))
color_mapping = {0: 'blue', 1: 'orange', 2: 'green', -1: 'grey'}
# Display the points
sns.scatterplot(
x=[point.x for point in points],
y=[point.y for point in points],
hue=[point.cluster for point in points],
palette=color_mapping,
)
# Display the centroids
sns.scatterplot(
x=[centroid.x for centroid in centroids],
y=[centroid.y for centroid in centroids],
hue=[centroid.cluster for centroid in centroids],
palette=color_mapping,
s=200,
marker="X",
edgecolor="black",
legend=False
)
if future_centroids is not None:
# Display the soon-to-be-centroid locations
sns.scatterplot(
x=[centroid.x for centroid in future_centroids],
y=[centroid.y for centroid in future_centroids],
hue=[centroid.cluster for centroid in future_centroids],
palette=color_mapping,
marker="D",
s=100,
edgecolors="k",
legend=False
)
# Plot dotted lines between current and future centroids
for i, centroid in enumerate(centroids):
plt.plot([centroid.x, future_centroids[i].x],
[centroid.y, future_centroids[i].y],
"k--", lw=1)
plt.show()
Alla olevassa kuvassa näkyvät kaikki iteraatiot (mukaan lukien aiempi), jotka näillä lähtöarvoilla käynnistetty silmukka tuotti.
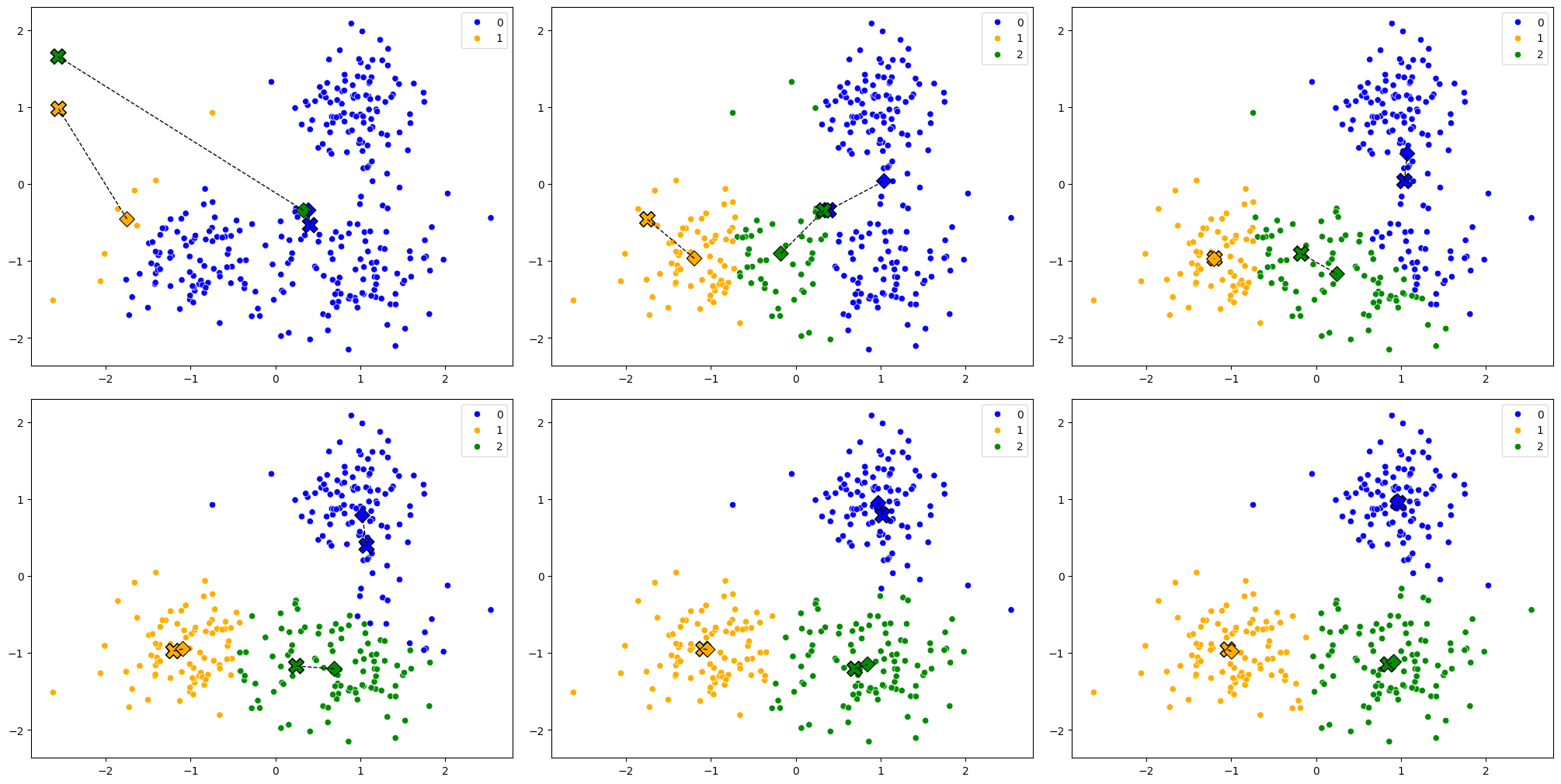
Kuva 3: Kaikki iteraatiot, jotka k-Means algoritmi tuotti. Jokainen klusterikeskus on merkitty ristillä ja neliöllä. Kannattaa avata kuva uudessa välilehdessä suurempana.
Tip
Tutustu myös muihin klusterointialgoritmeihin, kuten DBSCAN, vähintään pintaraapaisuna. Hyvä paikka aloittaa on Scikit-Learn: Clustering. Tarkkasilmäinen opiskelija löytää myös kurssikirjasta esimerkkejä toisen klusterointialgoritmin käytöstä.
Evaluointi
Huomaa, että todellisen klusteroinnin tapauksessa emme voi evaluoida mallin suoritusta vertaamalla sitä oikeaan ratkaisuun, koska kyseessä on ohjaamaton oppiminen. Jos meillä olisi havaintojen luokat jo tiedossa, meillä ei olisi syytä käyttää koko algoritmia luokitteluun. Toki esimerkiksi datan rakenteen tutkimiseen tai visualisointiin sitä voisi silti käyttää. Tässä esimerkissä me kuitenkin tiedämme, mikä on havaintojen alla piilevä logiikka, joten voimme verrata pisteille ennustettuja klustereita oikeisiin klustereihin.
Koodina sen voi tehdä käytännössä näin:
# Compare the labels to the predictions
correct = 0
for a, b in zip(predicted_points, actual_points):
if a.cluster == b.cluster:
correct += 1
print(f"Accuracy: {correct / len(points) * 100:.2f}%")
Kuvana se näyttäisi tältä:
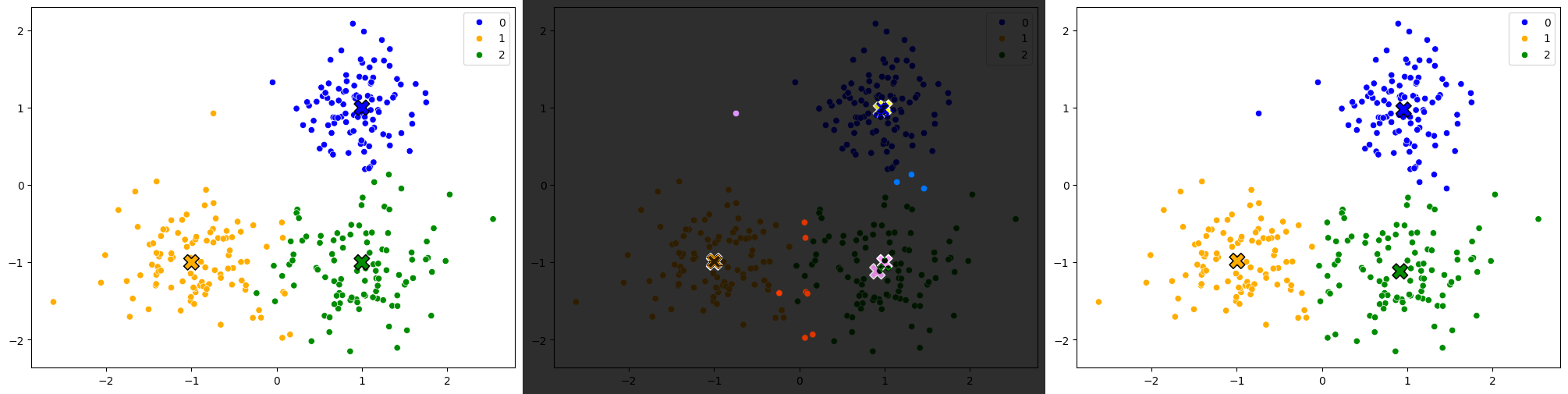
Kuva 4: Vertailu alkuperäisten klustereiden ja ennustettujen klustereiden välillä. Vasemmalla on alkuperäinen datasetti, oikealla ennustettu, ja keskellä on näiden RGB difference.
Warning
Muista kuitenkin, että "accuracyn" laskeminen klusteroinnin tapauksessa on hieman kyseenalaista monestakin syystä.
- Ilmiselvä syy on jo yllä mainittu, eli jos käytämme klusterointialgoritmia, niin meillä ei ole oikeaa vastausta.
- Toinen syy on, että vaikka meillä onkin dummy-dataa, niin klustereiden järjestys on täysin sattumanvarainen ja riippuu siitä, minne klusterikeskukset arvotaan. Olisi siis täysin mahdollista, että k-NN olisi arponut vasemman alalaidan klusterinkeskukseksi vihreän klusterin.
- Me olisimme voineet päättää segmentoida meidän pisteet kolmen klusterin sijasta kahteen, neljään tai johonkin muuhun
k=n-määrään. Nämä eivät olisi sen enempää oikeita tai vääriä vastauksia; me saisimme vain ryhmiä, joissa on enemmän tai vähemmän varianssia.
Kuinka valita k?
Olettaen, että ns. ground truth eli annotoitu data puuttuu, arvon \(k\) valinta on haaste. Tähän löytyy eri keinoja, joista esittelen elbow-metodin, jonka voisi kääntää kyynärpäämenetelmäksi, ja silhuoutte scoren, joka käännettäköön siluettiarvoksi.
Kyynärpäämenetelmä
xychart
x-axis "k" [2, 3, 4, 5, 6, 7, 8, 9, 10]
y-axis "Neliövirheiden summa" 0 --> 2500
bar [2400, 980, 380, 300, 260, 195, 182, 175, 165]
line [2400, 980, 380, 300, 260, 195, 182, 175, 165]Elbow-metodi on yksinkertainen. Aja k-means eri \(k\) arvoilla, ynnää kaikkien pisteiden etäisyyden klusterikeskukseen, ja piirrä näistä kuvaaja. Yllä olevan kuvaajan kohdalla kuvaajan "kyynärpää" – tai jääkiekkomailan mutka – on noin luvun 4 kohdalla. 4 5 Y-akselista voi käyttää myös nimitystä inertia.
Siluettiarvo
xychart
x-axis "k" [2, 3, 4, 5, 6, 7, 8, 9, 10]
y-axis "Siluettiarvo" 0.32 --> 0.6
bar [0.57, 0.51, 0.409, 0.331, 0.325, 0.327, 0.339, 0.336, 0.329]
line [0.57, 0.51, 0.409, 0.331, 0.325, 0.327, 0.339, 0.336, 0.329]Siluettiarvo lasketaan ensin jokaiselle pisteelle erikseen – jolloin se on tarkemmin otettuna siluettikerroin – ja lopuksi näistä yksittäisten näytteiden arvoista lasketaan keskiarvo. Yllä olevassa kuvitteellisessa esimerkissä \(k=5\) siluettiarvo on selvästi laskenut, joten \(2 < k < 4\) voisi olla järkevä alue, jolta valita \(k\). 6
Yhden pisteen \(x\) kohdalla lasketaan ensin kaksi suuretta:
- \(a(x)\): pisteen keskimääräinen etäisyys oman klusterin muihin pisteisiin
- \(b(x)\): pisteen keskimääräinen etäisyys lähimmän muun klusterin pisteisiin
Jos käytämme euklidista etäisyyttä, siluettiarvo pisteelle \(x\) on 6
Tämän kaavan idea on yksinkertainen:
- jos piste on lähellä omaa klusteriaan, \(a(x)\) on pieni
- jos piste on kaukana muista klustereista, \(b(x)\) on suuri
- tällöin siluettiarvo, välillä \(-1\) ja \(1\), on suuri, mikä viittaa hyvään klusteroitumiseen
Lopullinen siluettiarvo saadaan ottamalla kaikkien pisteiden siluettiarvojen keskiarvo. 6 Jos lopun keskiarvo jätetään laskematta, meillä on käsissämme siluettikertoimet (engl. silhouette coefficients), jotka järjestämällä voi piirtää silhouette diagrammin. 5 Tästä löytyy esimerkki scikit-learnin dokumentaatiosta Selecting the number of clusters with silhouette analysis on KMeans clustering.
Tehtävät
Tehtävä: k-Means from scratch
Avaa 510_kmeans_from_scratch.py ja tutustu siihen. Notebookissa on toteutettu k-Means-algoritmi alusta alkaen, ilman Scikit Learn -kirjastoa. Piirrä drawdata-widgetillä uusi dataset. Tustutus elbow- ja siluettiarvot piirtäviin kuvaajiin ja tutustu, kuinka eri muotoiset datasetit jaetaan klustereihin eri \(k\)-arvoilla.
Tämä, aivan kuten edellisetkin kurssin Notebookit, ovat täysin sinun muokattavissasi. Kenties voisi olla mielenkiintoista tehdä Notebookista variantti, jossa algoritmin voi valita vetovalikosta: k-means, DBSCAN, Agglomerative Clustering, MeanShift, tai jokin muu.
Tehtävä: Tikkurilan värikartta
Avaa 511_color_swatch.py ja jatka toteutusta. Ensimmäiset solut neuvovat, kuinka OpenCV:llä ladataan kuva ja muunnetaan se RGB-, HSV- ja LAB-koordinaatistoihin. Käyttäen näitä värien representaatioita, sinun tulee kouluttaa kolme eri mallia, jotka klusteroivat kuvan värit \(k\) klusteriin. Kun käännät kuvan kunkin pikselin osan klusterinsa väriseksi, ja järjestät ne määrän mukaan, sinulla on kädessäsi värikartta. Moni suomalainen tuntee tämän lopputuloksen nimellä Tikkurilan värikartta.
Idea on, että jos haluaisit maalata huoneen annetun referenssikuvan väreillä, malli klusteroi värit, joita sinun tulisi käyttää. Ihmisen värinäkö on kuitenkin huomattavan monimutkainen järjestelmä. Pelkkien RGB-arvojen klusterointi ei välttämättä onnistu löytämään niitä värejä, jotka ihminen kokee kuvan dominoivina väreinä. Tämän vuoksi on syytä tutustua myös HSV- ja LAB-värimalleihin. Jos RGB, HSV ja LAB värimallit ovat sinulle aivan vieraita, voit aloittaa vaikkapa värislidereitä säätämällä esimerkiksi colorizer.org -sivustolla. Saatat myös joutua painottamaan esimerkiksi Hue-arvoa tai LAB:n Lightness-arvoa. Muista, että Hue on syklinen piirre: sinun tulee muuntaa se sin ja cos -koordinaateiksi.
Skriptin luomaa värikarttaa voisi myöhemmin käyttää esimerkiksi:
- Huoneen väriteeman määrittelyyn (ks. Kuva 3 alta)
- Web-sivuston graafisessa ohjeistuksessa
- Elokuvan värimäärittelyn ohjenuorana
Alla on selvyyden vuoksi esimerkki, miltä lopputulema voisi vaikuttaa HSV:n osalta.

Kuva 1: Terry Kearneyn kuva, otsikolla 5 A Day, on tekijänoikeusvapaa kuva ja se on ladattavissa Flickr-palvelusta: Terry Kearney: 5 A Day.

Kuva 2: Yllä olevasta kuvasta muodostettu 4 värin kartta. Värikartan värit on klusteroitu k-Means-algoritmilla käyttäen HSV-koordinaatistoa.

Kuva 3: Värikartan perusteella luotu sisustuskuva. Kuva on GPT-5.4:llä generoitu.
Lähteet
-
Kämäräinen, J. Koneoppimisen perusteet. Otatieto. 2023. ↩↩↩↩
-
Guérin, A., Chauvet, P. & Saubion, F. A Survey on Recent Advances in Self-Organizing Maps. https://arxiv.org/abs/2501.08416 ↩
-
Reddy, C. K., Vinzamuri, B. & Reddy, C. K. A Survey of Partitional and Hierarchical Clustering Algorithms. CRC Press. 2014. https://doi.org/10.1201/9781315373515-4 ↩
-
Grus, J. Data Science from Scratch 2nd Edition. O'Reilly Media. 2019. ↩↩
-
Géron, A. Hands-On Machine Learning with Scikit-Learn and PyTorch. O'Reilly. 2025. ↩↩
-
Bonaccorso, G. Machine Learning Algorithms, 2nd edition. Packt Publishing. 2018. ↩↩↩